Scrapping, API
Jeux de données à mettre en forme (séance 1) vs.
Jeux de données à construire (séance 2).
Où trouver des données sur le web ?
- Instituts publics : INSEE , IGN , ...
- Portails open-data : data.iledefrance.fr , data.gouv.fr , ...
- Sites collaboratifs : Wikipedia (dbpedia) , OpenStreetMap , ...
- Sites specialisés : Météo , Football , Logement , Annonces , ...
- Réseaux sociaux : Twitter , FlickR , foursquare , ...
- Moteur de recherche : Google , Yahoo , Bing , ...
- API spécialisées : Velib , Deliveroo , ...
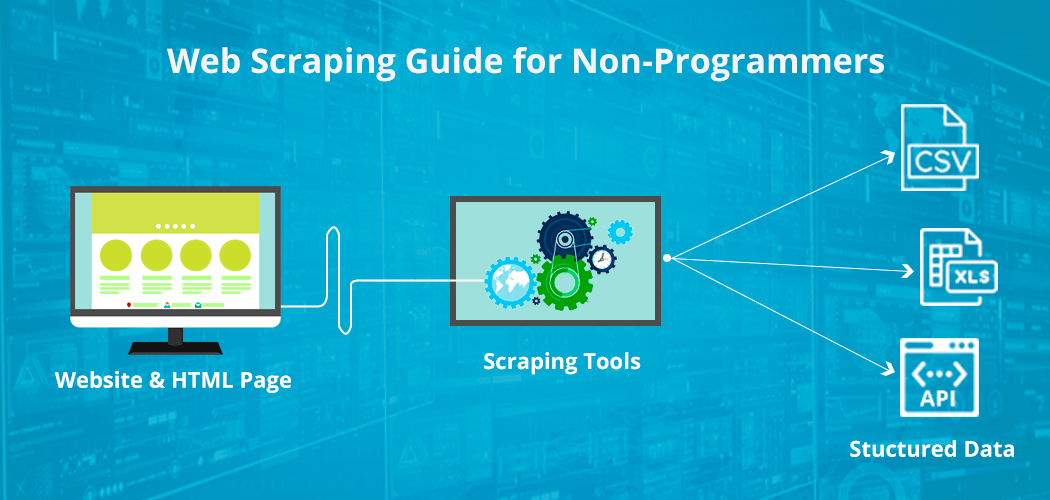
Scraping
= Extraire des informations spécifiques d'une ou plusieurs pages web en vu de constituer un jeu de données.
Scraping, le HTML
<!DOCTYPE html>
<head><meta charset="utf-8"><title>Titre<title></head>
<body>
<section style="padding-top:6em;text-align:center">
<h1 class="purple"> Scrapping </h1>
<h4 class="purple">Extraire des informations spécifiques</h4>
<h4 class="purple">d'une ou plusieurs pages web</h4>
<h4 class="purple">en vu de constituer un jeu de données</h4>
</section>
</body>
</html>Apprendre le HTML (et CSS, et...)
...Plein d'autres choix : Google it.
Scraping : les packages RCurl et XML (le retour)
RCurl (Client URL Request Library)
# Récupérer une page
library(RCurl)
res = getURL("http://www...")
# Alternative sans RCurl :
library(httr)
res = rawToChar(GET("http://www...")$content)XML : htmlTreeParse, getNodeSet
library(XML) #TODO: utiliser plutôt xml2
# Parse du html
resp = htmlTreeParse(res, useInternal=T)
# Fonction de haut niveau pour récupérer les tableaux
resp = readHTMLTable(resp)
# Récupérer le noeud désiré (xpath)
node = getNodeSet(resp, '//nav/ul/')Package alternatif : rvest (= httr + XML)
Xpath : extraire des informations d'un arbre DOM
Syntaxe pour se promener dans l'abre DOM et en extraire des parties (noeuds, attributs, ...) ; plus de détails sur w3schools.
| Expression | Description |
|---|---|
| nodename | Selects all nodes with the name "nodename" |
| / | Selects from the root node |
| // | Selects nodes in the document from the current node that match the selection |
| . | Selects the current node |
| .. | Selects the parent of the current node |
| @ | Selects attributes |
Exemples
| Expression | Description |
|---|---|
| /bookstore/book[1] | Selects the first book element that is the child of the bookstore element. |
| /div/div[3]/p | Selects the first child 'p' of the third 'div' child of the first 'div' tag. |
| //title[@lang] | Selects all the title elements that have an attribute named lang |
| //title[@lang='en'] | Selects all the title elements that have an attribute named lang with a value of 'en' |
| /bookstore/book[price>35.00] | Selects all the book elements of the bookstore element that have a price > 35.00 |
library(httr) #récupère un contenu
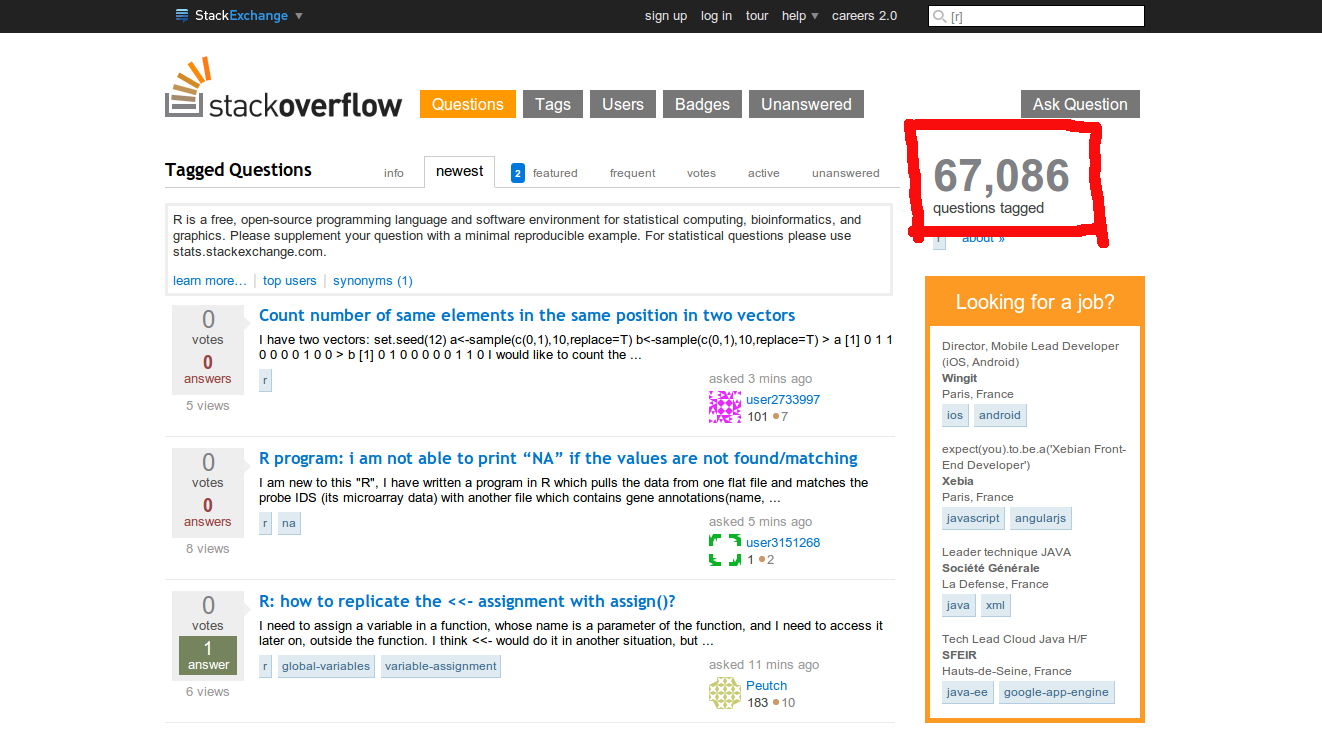
library(XML) #parse ce contenuExercice : scraper stackoverflow.com
Ecrire un script R permettant de scraper le nombre de questions
publiées sur le site pour chacun des tags suivants :
python, julia-lang, r, sas, matlab.
Réaliser un graphique à partir de ces données.
Exercice : scraper stackoverflow.com - corrigé
# Définition des termes à scrapper
languages = c('python','julia-lang','r','sas','matlab')
# Initialisation de la table (liste)
langCount = list()
# Boucle sur les termes
base = "https://stackoverflow.com/questions/tagged/"
for (lang in languages) {
# Récupérer la page
res = httr::GET(paste0(base,lang))
# Parser puis récupérer le noeud désiré (xpath)
resp = htmlParse(res)
ns1 = getNodeSet(resp, "//*[@id='mainbar']/div[4]/div[1]/div[1]")
# Alt: ns1 = getNodeSet(resp, '//div[contains(@class, "fs-body3")]')
# Récupérer la valeur et la nettoyer
val = xmlValue(ns1[[1]])
valclean = gsub("questions","",val)
valclean = gsub("[ \n\r,]","",valclean)
langCount[[lang]] = as.numeric(valclean)
}
# Faire un graphique
counts = sort(unlist(langCount), decreasing=T, index.return=T)
date = format(Sys.time(), "%d/%m/%Y")
title = paste("Popularité sur stackOverFlow",date)
barplot(counts$x,names.arg=languages[counts$ix],
main=title,ylab="Nombre de questions")
# Ou :
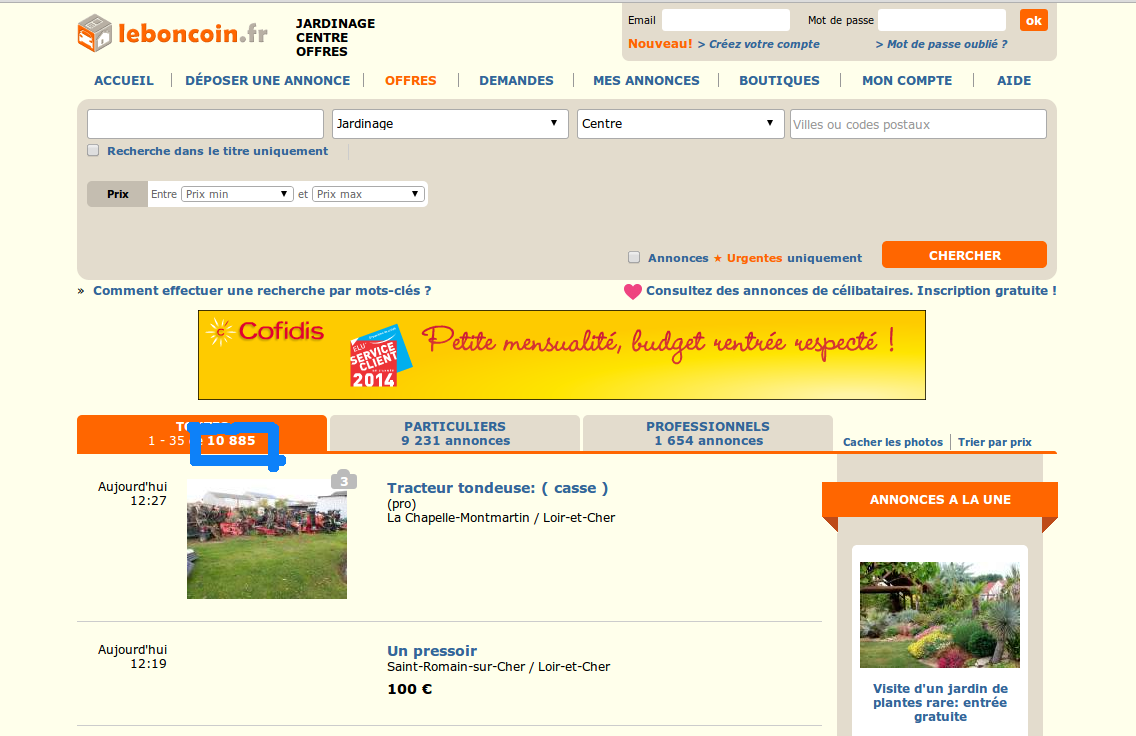
#pie(counts$x,labels=languages[counts$ix],main=title)Exercice : scraper leboncoin.fr
Ecrire un script R permettant de scraper le nombre d'annonces de particuliers dans la catégorie "Jardinage" en région Centre.
Exercice : scraper leboncoin.fr - corrigé
"Impossible" : nécessite des techniques plus avancées...
(Twitter également).
Problèmes (potentiels - liste non exhaustive !) :
- Pièges "honeypot" : faux liens. Pas très grave dans notre cas.
- Login obligatoire : contournable.
- AJAX : nécessite de simuler un navigateur avec javascript activé, et d'attendre le chargement complet de la page.
- CAPTCHA : bloquant sauf via algorithmes de ML adaptés.
- ...
Complément scraping
Contournement AJAX (attendre que la page se charge).
from selenium import webdriver ; import time
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.service import Service
from webdriver_manager.firefox import GeckoDriverManager
browser = webdriver.Firefox(service=Service(GeckoDriverManager().install()))
browser.get('https://www.nba.com/stats/players/traditional/?PerMode=Totals&sort=PTS&dir=-1')
# ...Et leboncoin ?!
#browser.get('https://www.leboncoin.fr/recherche?text=jardinage&locations=r_7')
#...AlloCiné ?
#browser.get('https://www.allocine.fr/film/fichefilm_gen_cfilm=10568.html')
#browser.execute_script("Didomi.setUserAgreeToAll()")
time.sleep(2)
df = []
table = browser.find_elements(By.CLASS_NAME, "nba-stat-table")
.find_elements(By.XPATH, "//table")
for row in table.find_elements(By.XPATH, "//tr"):
line = []
for col in row.find_elements(By.XPATH, "//td"):
line.append(col.text)
df.append(line)
print(df) #...
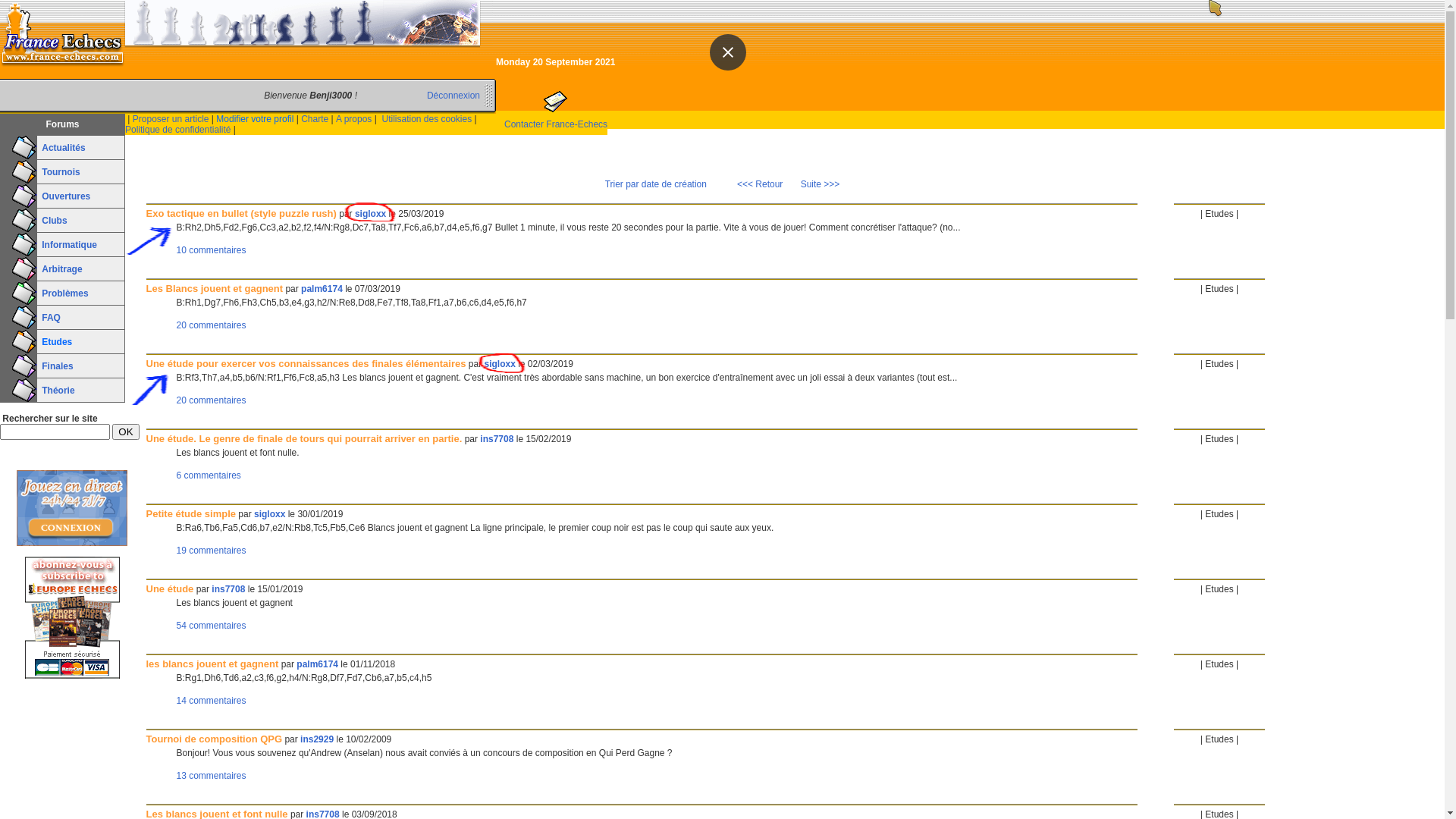
#browser.close()Exercice : scraper france-echecs.com
Écrire un script R permettant de récupérer les premières lignes de
chaque sujet lancé par sigloxx dans la rubrique Études.
Ensuite (ou en même temps), retrouvez aussi les titres, URLs et dates.
Exercice : scraper france-echecs.com - corrigé
# Par essais-erreurs (dichotomie), on trouve 36 pages.
base = "https://www.france-echecs.com/index.php?tri=datecreation&rub=9&p="
dates = c()
titres = c()
urls = c()
firstLines = c()
for (page in 1:36) {
# Récupérer la page
res = httr::GET(paste0(base,page))
resp = htmlParse(res) #ou htmlTreeParse pour objet R
# Liste des auteurs :
auteurs = sapply( getNodeSet(resp, "//span[@class='soustitre']"), xmlValue )
# Lignes d'intérêt :
ns1 = getNodeSet(resp, "//table[3]/tr/td[2]/table")
# Enfants = éléments <tr>
trArray = xmlChildren(ns1[[1]])
# Indices à regarder parmi ces lignes :
indices = 2 + 4 * (which(auteurs == "sigloxx") - 1) + 2
for (i in indices) {
tr = xmlToList(trArray[i]$tr)
titres = c(titres, tr$td$nobr[[1]][[1]][[1]])
urls = c(urls, as.character(tr$td$nobr[[1]][[1]][[2]][2]))
dates = c(dates, substr(tr$td$nobr[[5]][["data-date14"]], 1, 8))
firstLines = c(firstLines, xmlValue(trArray[i+1]))
}
}
df = data.frame(date=dates, titre=titres, url=urls, firstlines=firstLines)Correction alternative avec rvest
library("rvest")
base = "https://www.france-echecs.com/index.php?tri=datecreation&rub=9&p="
df = data.frame("Titre" = c(), "Auteur" = c(), "Date" = c(), "Texte" = c())
for (p in 1:36) {
url = paste0(base, p)
site = read_html(url)
auteur_art = site %>% html_elements("span.soustitre") %>% html_element("a")
texte_art = site %>% html_elements("blockquote")
titre_art = site %>% html_elements("a.titre")
date_art = site %>% html_nodes("span.date14GmtToLocal") %>%
html_attr("data-date14") %>% substring(.,1,8) %>%
as.Date(.,format = ("%Y %m %d"))
filter = html_text(auteur_art) == "sigloxx"
df = rbind(df,
data.frame("Titre" = html_text(titre_art[filter]), "Auteur" = html_text(auteur_art[filter]),
"Date" = date_art[filter], "Texte" = html_text(texte_art[filter])))
}
# Ou, sans filtre (mais construit toute la df d'abord...) :
#df = ... %>% filter(Auteur == "sigloxx")API = Application Programming Interface
→ Interroger un serveur donnant une information précise.
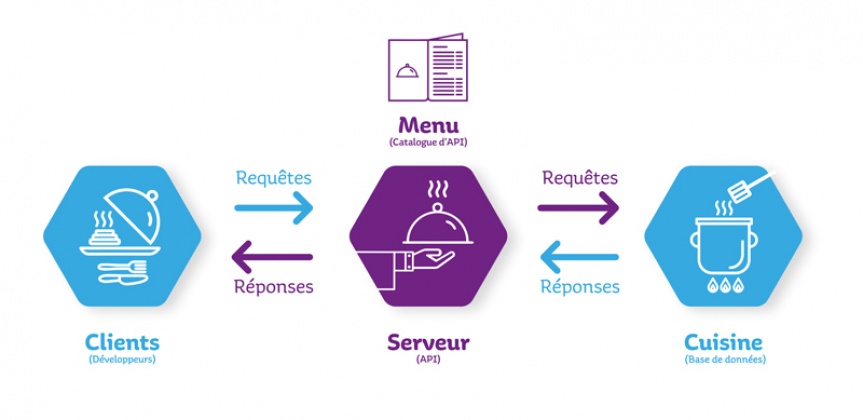
Premier exemple :
> base = "https://evilinsult.com/generate_insult.php/?"
> RCurl::getURLContent(paste0(base,"lang=el"))
> #ou rawToChar(httr::GET(...)$content)
Πόσο χρονών είσαι ?
> rjson::fromJSON( RCurl::getURLContent(paste0(base,"lang=el&type=json")) )
{
"number":"22",
"language":"el",
"insult":"\u03a1\u03b5
\u03ba\u03b1\u03c1\u03ac\u03b2\u03bb\u03b1\u03c7\u03b5
\u03c4\u03b7\u03c2
\u03b3\u03b5\u03b9\u03c4\u03bf\u03bd\u03b9\u03ac\u03c2!",
"created":"2021-09-21 08:47:02",
"shown":"379",
"createdby":"emorfili",
"active":"1",
"comment":"You ridicule of the neighborhood"
}Note : Un outil intéressant pour décoder l'unicode.
The Datamuse API is a word-finding query engine for developers. You can use it to find words that match a given set of constraints and that are likely in a given context. Applications :
- autocomplete on text input fields, search relevancy ranking,
- assistive writing apps, word games, ...
> base = "https://api.datamuse.com"
# Words that start with t, end in k, and have 3 letters in between
> L = rjson::fromJSON( getURLContent(paste0(base,"/words?sp=t???k")) )
> length(L) #57
> L[[2]]
$word
[1] "track"
$score
[1] 4055
# Words that often follow "drink" in a sentence, that start with the letter w
> L = fromJSON( getURLContent(paste0(base,"/words?lc=drink&sp=w*")) )
> length(L) #12
> L[[3]]
$word
[1] "wine"
$score
[1] 8740Exercice : API arXiv
Classer (tous) les co-auteurs de Camille Coron par nombre de publications décroissantes.
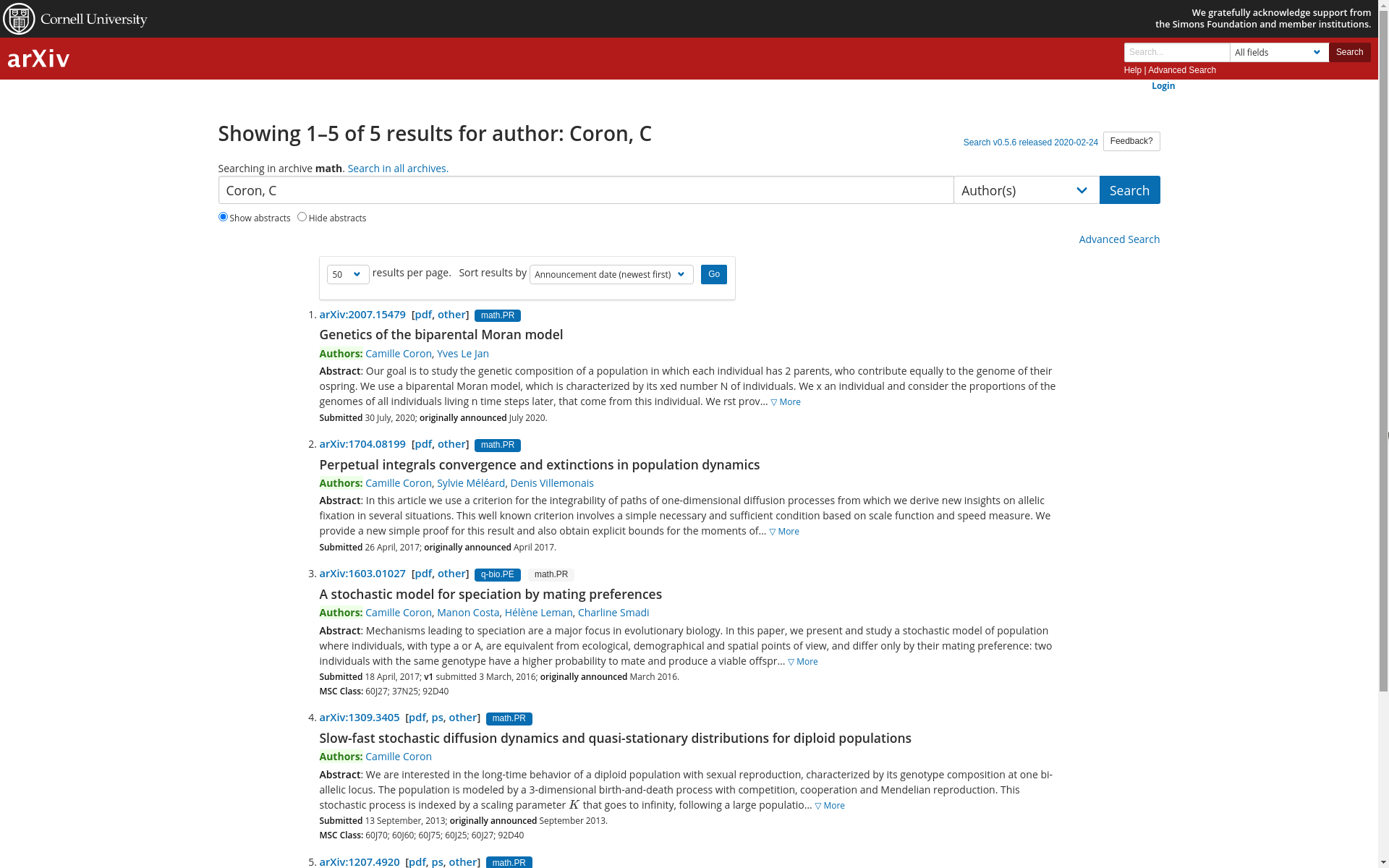
Exercice "co-auteurs" corrigé
base = "https://export.arxiv.org/api/query?"
# 1) Récupération des articles de Camille + lister co-auteurs
x = XML::xmlTreeParse( RCurl::getURLContent(
paste0(base,"search_query=au:camille+AND+au:coron") ) )
entries = x$doc$children$feed
indices = (1:length(entries))[names(entries) == "entry"]
coauthors = c()
for (i in indices) {
L = xmlToList( entries[[i]] )
auth_idx = (1:length(L))[names(L) == "author"]
for (a in auth_idx) {
name = L[[a]]$name
print(name)
if (name != "Camille Coron") coauthors = c(coauthors, name)
}
}
coauthors = iconv( unique(coauthors), "UTF-8", "ASCII//TRANSLIT" )
# 2) Compter les articles des co-auteurs
nbArticles = c()
for (author in coauthors) {
search_str = gsub(" ", "+AND+", author)
xx = xmlTreeParse(getURLContent(paste0(
base,"search_query=au:",search_str,"&max_results=9999")))
nbArticles = c(nbArticles, sum( names(xx$doc$children$feed) == "entry" ))
}
s = sort(nbArticles, index.return=T, decreasing=T) #see also 'order()'
df = data.frame(coauthor=coauthors[s$ix], nbarticles=nbArticles[s$ix])...Encore un souci ?!
Exercice : performance moyenne
Calculer la performance moyenne réalisée par AnnieStarlight sur l'ensemble des tournois auxquels iel a participé, à la cadence Blitz.
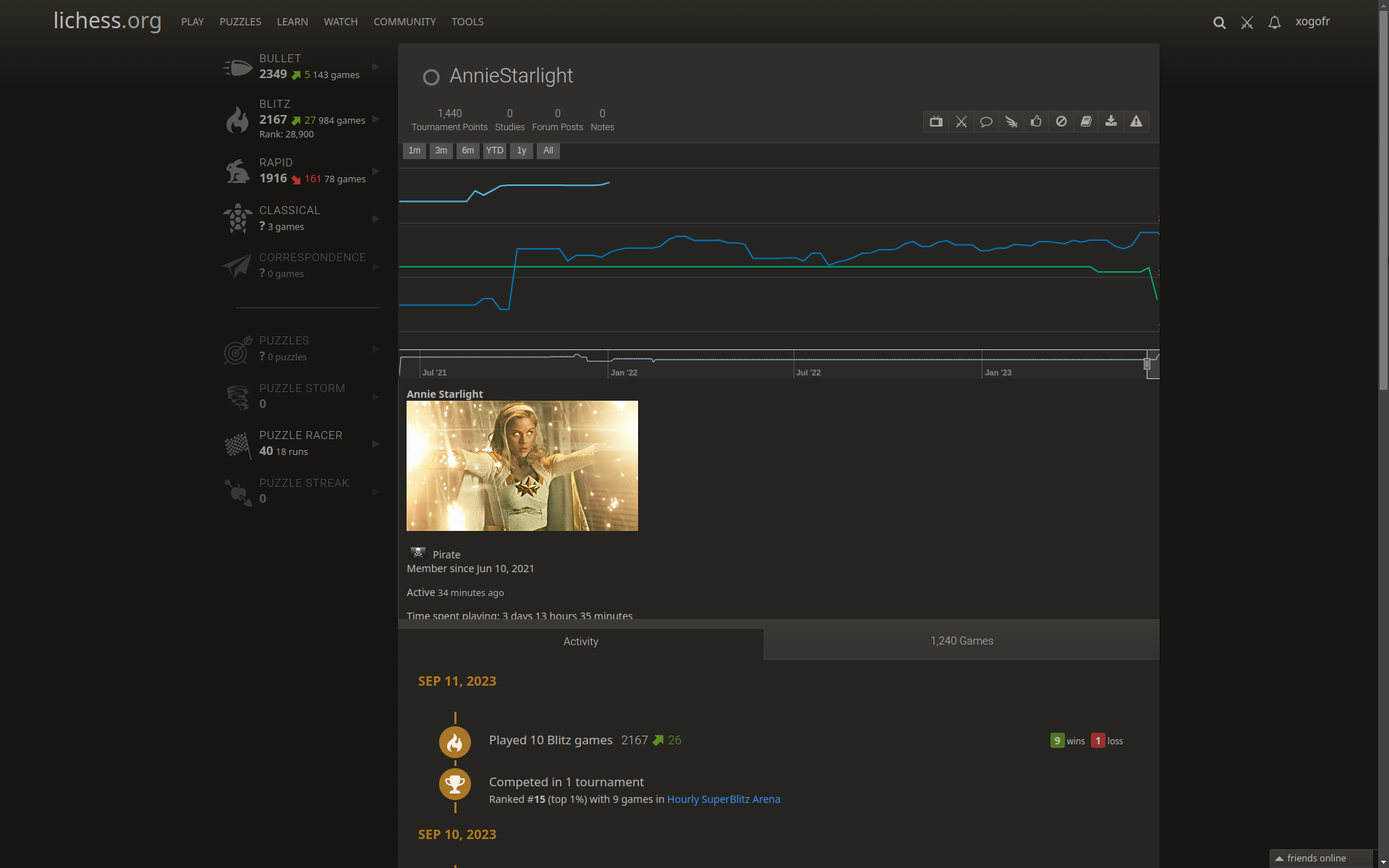
(Créer un compte accélère la recherche).
Exercice : performance moyenne - corrigé
httr::add_headers('Bearer YOUR_SECRET_TOKEN')
allGames = RCurl::getURLContent(
"https://lichess.org/api/games/user/AnnieStarlight?perfType=blitz&rated=true", binary=F)
gameArray = strsplit(allGames, "\n\n\n")
trefs = c()
for (game in gameArray[[1]]) {
gameId = substr(
stringr::str_extract(game, "lichess.org/[a-zA-Z0-9]{8,8}"),
13, 21)
# Scraping pour (tenter de) récupérer l'ID du tournoi associé
gamePage = RCurl::getURLContent(paste0("https://lichess.org/", gameId)
if (str_detect(gamePage, "game__tournament-link")) {
x = XML::htmlParse(gamePage)
nodeSetLink = getNodeSet(x, "//section[@class='game__tournament-link']/a[1]")
trefs <- c(trefs, xmlAttrs(nodeSetLink[[1]])[3])
}
}
trefs = unique(trefs)
perfs = c()
for (tid in trefs) {
httr::add_headers('Bearer YOUR_SECRET_TOKEN')
tres = getURLContent(paste0("https://lichess.org/api/",tid,"/results"), binary=F)
tresArray = strsplit(tres, "\n\n\n")
index = which(str_detect(tresArray[[1]], "AnnieStarlight"))
perfs = c(perfs, fromJSON(tresArray[[1]][index])$performance)
}
mean(perfs) ; sd(perfs)Exercice : système de recommandation
Dans un premier temps (initialisation), cherchez via l'API des pistes susceptibles de vous plaire (genre, artiste...).
Ensuite, cherchez les (URL des) 5 pistes les mieux notées parmi celles similaires au choix initial. Note = score moyen.
(Nécessite de créer un compte développeur).
Exercice : système de recommandation - corrigé
# Étape 1 : trouver les (identifiants de) pistes
baseUrl = "https://api.jamendo.com/v3.0/tracks/
?client_id=CLIENT_ID&format=json&limit=20&groupby=artist_id&"
trackIds = c()
for (searchStr in c("xartist=Daft+Punk",
"vocalinstrumental=vocal&gender=female&speed=low+medium")
{
json = getURLContent(paste0(baseUrl, searchStr))
res = rjson::fromJSON(res)
for (track in res$results)
trackIds = c(trackIds, as.integer(track$id))
}
# Étape 2 : chercher les pistes similaires.
baseUrl = "https://api.jamendo.com/v3.0/reviews/tracks/?
client_id=CLIENT_ID&format=json&limit=3&track_id="
simTracks = c()
for (track in trackIds) {
json = getURLContent(paste0(baseUrl, track))
res = rjson::fromJSON(res)
for (track in res$results)
simTracks = c(simTracks, as.integer(track$id))
}
simTracks = setdiff(simTracks, trackIds)Exercice : système de recommandation - corrigé (suite...)
# Étape 3 : classer les pistes similaires
baseUrl = "https://api.jamendo.com/v3.0/reviews/tracks/?
client_id=CLIENT_ID&format=json&limit=all&order=score_desc"
scores = c()
for (track in simTracks) {
json = getURLContent(paste0(baseUrl, track))
res = rjson::fromJSON(res)
scores = c(scores, mean(sapply(res$results, function(o) o$score)))
}
s = sort(scores, index.return=T, decreasing=T)
paste0("https://www.jamendo.com/track/", simTracks[s$ix[1:5]])Aller plus loin
Vous pouvez faire le même genre d'exercice avec une des APIs présentées sur cette page.
Possible aussi : Facebook, Twitter, YouTube etc.
A priori plus complexe, mais même principe.