Base de données relationnelles
- Développées dans les années 70.
- Stockage structuré de volumes (potentiellement) importants.
- Éviter la redondance.
- Inspirées de l'algèbre relationnelle.
- ~ Standardisée avec le langage SQL.
- Difficulté de distribuer sur plusieurs machines
→ Développement des bases noSQL : Mongo, Cassandra, ...
Différents systèmes de gestion de base de données (SGBD) :
- Libres : MariaDB, PostgreSQL, ...
- Propriétaires : Oracle, Microsoft SQL Server, ...
Pour cette séance : SQLite.
Avantage : pas de serveur à configurer, tout dans un fichier.
(Inconvénient : pas de sécurité...).
Algèbre Relationnelle
Relations (ou tables) :
Ensemble de n-uplets
Algèbre
Définition d'opération élémentaires permettant d'extraire les
informations recherchées.
Ces opérations prennent une (opérateurs unaires) ou deux relations
(opérateurs binaires) et fournissent une relation en résultat.
Opérations unaires
À partir d'un ensemble $A$, obtenir un ensemble $B$ :
- Sélection, $B=\sigma_s(A)$ :
N-uplets de $A$ qui correspondent à certains critères.
→ Suppression de lignes. - Restriction, $B=\pi_r(A)$ :
N-uplets contenant certaines composantes des n-uplets de $A$.
→ Suppression de colonnes.
Opérations binaires
À partir des ensembles $A$ et $B$, obtenir un troisième ensemble $C$.
- Union, $C=A \cup B$ :
N-uplets présents dans $A$ ou dans $B$. - Différence, $C = A - B$ (ou $A \backslash B$) :
N-uplets présents dans $A$ mais absents de $B$. - Produit cartésien, $C = A \times B$ :
Toutes les combinaisons possibles des n-uplets de A avec ceux de B.
Opérations binaires dérivées
À partir des ensembles $A$ et $B$, obtenir un ensemble $C$.
- Jointure, $C=A \bowtie_q B = \sigma_q(A \times B)$ :
Sous-ensemble du produit cartésien vérifiant la condition $q$. - Intersection, $C = A \cap B = A - ( A - B )$ :
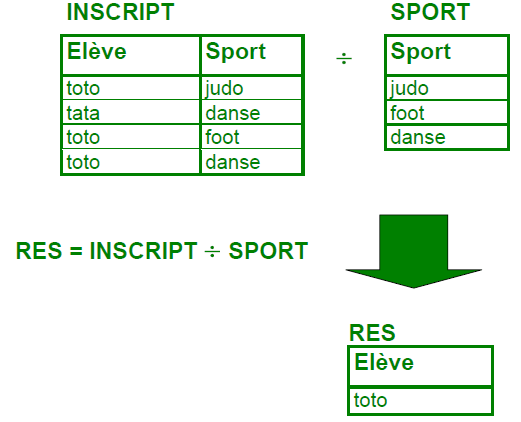
N-uplets présents à la fois dans $A$ et dans $B$. - Division, $C = A \div B = \pi_r(A) - \pi_r((\pi_r(A)\times B)-A)$ :
N-uplets qui concaténés à tous ceux de $B$ sont encore dans $A$.
Exemple de division / source
SQL : Structured Query Langage
Interrogation des données
SELECT * FROM table WHERE conditionsDéfinition de la structure des données
CREATE TABLE, ALTER TABLE, DROP TABLEManipulation des données (C.R.U.D)
INSERT, UPDATE, DELETE+ Contraintes (d' intégrité).
+ Gestion des droits.
Structure d'une requête simple
-- Sélection des attributs (restriction)
SELECT attr1 as a, attr2 as b
-- Liste des relations concernées par la requête
FROM table1 as t1, table2 as t2
-- Opération de sélection (conditions)
WHERE t1.a = t2.b AND t1.attr3 > 5Le résultat est l’ensemble de TOUS les n-uplets (pas de suppression des doublons) restreints respectant la condition.
La clause WHERE
Les différents opérateurs :
- Opérateurs relationnels : <, <=, =, <>, >=, >
- Opérateurs arithmétiques : +, -, *, /
- Opérateurs logiques : AND, OR, NOT
- Autres : LIKE, BETWEEN, IS NULL, IN, EXISTS, ...
Like = matching partiel sur les chaînes de caractères :
SELECT NomF, VilF, AdrF FROM Fournisseur
WHERE VilF LIKE 'Saint%' OR VilF LIKE '_a%'Between = condition sur un intervalle :
SELECT * FROM Fournisseur
WHERE NomF BETWEEN 'A%' AND 'G%'Produit cartésien
From + plusieurs tables : possibilité d'utiliser des alias (as)
-- Exemple :
SELECT f.NomF, f.VilF, l.NomP FROM Fournisseur AS f, Livraison AS l...À éviter !
Jointure
Produit cartésien + where "foreign.key=primary.key" :
SELECT f.NomF, f.VilF, l.NomP
FROM Fournisseur AS f
JOIN Livraison AS l
ON f.NoF = l.NoF --ou USING(NoF)Possibilité de rajouter des conditions :
SELECT f.NomF, f.VilF, l.NomP
FROM Fournisseur AS f
JOIN Livraison AS l
USING(NoF) --ou ON f.NoF = l.NoF
WHERE f.VilF LIKE 'P%'Attention : ne pas utiliser 'WHERE' pour la condition de jointure.
GROUP BY
Plusieurs possibilités :
- Comptage : COUNT, COUNT DISTINCT
- Arithmétique : AVG, SUM, ...
- Conditions sur le groupe : HAVING
Exemples :
-- Comptage des fournisseurs par ville :
SELECT COUNT(DISTINCT NomF), VilF
FROM Fournisseur
GROUP BY VilF
-- Comptage des fournisseurs pour les villes ayant + de 5 fournisseurs :
SELECT COUNT(DISTINCT NomF), VilF
FROM Fournisseur
GROUP BY VilF
HAVING COUNT(DISTINCT NomF)>5ORDER BY
Tri de la table
- DESC : descending, ASC : ascending (défaut).
- LIMIT : pour limiter le nombre de résultats retournés.
Exemples :
SELECT NomF, VilF, AdrF
FROM Fournisseur
WHERE VilF LIKE 'Saint%'
ORDER BY NomF DESC
LIMIT 10Chaînes de charactères et dates
! Pas uniformisé entre les différents système de BDD.
Concatenation :
- || : sqlite, PostgreSQL, ...
- CONCAT() : MySQL, PostgreSQL, ...
Dates :
- STRFTIME('%s',attr), DATE(attr) : sqlite
- DATE_FORMAT(attr,'%H'), DATE_SUB(attr1,attr2) : MySQL
Exemples (SQLite) :
SELECT MIN(strftime('%s',l.Date)), VilF, AdrF, NomF
FROM Livraison AS l, fournisseur AS f
GROUP BY NomFDéfinition d'un schéma
- Définition des variables (+ type).
- Contraintes d'unicité.
- Primary key, Foreign key.
- Index.
Exemples :
CREATE TABLE artist(
artistid INTEGER PRIMARY KEY,
artistname TEXT
);
CREATE UNIQUE INDEX artistname ON artist(artistname);
CREATE TABLE track(
trackid INTEGER,
trackname TEXT,
trackartist INTEGER,
FOREIGN KEY(trackartist) REFERENCES artist(artistid)
);Opérations C.R.U.D
- Create : CREATE
- Read : SELECT
- Update : UPDATE
- Delete : DELETE
Exemples
-- Mise à jour
UPDATE artist SET artistname = 'unknown' WHERE artistname = ''
-- Suppression
DELETE FROM artist WHERE artistname = ''Chargement d'une base
À l'invite de commande sqlite3 :
.read fichier.sql
.schema --affiche un résumé des tablesPackage sqldf
- Permet de faire des opérations "comme dans une base".
- ! $\neq$ driver
- Opère sur et retourne des data.frame
# Chargement du package
library(sqldf)
# Import à partir d'un fichier
routes = read.csv("../data/exo4.gtfs/routes.txt")
sqldf("select route_id, route_desc from routes limit 5")Importer les données du dossier ch2_exo_gtfs
La structures des tables correspond à celle du format gtfs défini ici https://developers.google.com/transit/gtfs/
Importation des données
À partir d'un fichier ?
path = "../data/exo4.gtfs/" #à changer
routes = read.csv(paste0(path, "routes.txt"))
# ...
trips = read.csv(paste0(path,"trips.txt"))Ou bien dans sqlite3 :
.mode csv
.import routes.txt routes
-- ...
.import trips.txt tripsCombien de trips, routes et stops ?
SELECT COUNT(*) FROM trips# En R, en utilisant sqldf :
sqldf("select count(*) from trips")
sqldf("select count(*) from routes")
sqldf("select count(*) from stops")Afficher les 5 premières lignes de la table stop_time.
SELECT * FROM stop_times LIMIT 5sqldf("select trip_id,arrival_time
from stop_times
limit 5")Combien d'arrêts dans chaque trip ?
SELECT COUNT(*) AS nbstops, *
FROM stop_times
GROUP BY trip_idquery = "select count(*) as nbstops, trip_id
from stop_times
group by trip_id"
sqldf(query)Le trip avec le + de stops ?
SELECT COUNT(*) AS nbstops, *
FROM stop_times
GROUP BY trip_id
ORDER BY nbstops DESC
LIMIT 1query = "select count(*) as nbstops, *
from stop_times
group by trip_id
order by nbstops desc
limit 1"
sqldf(query)Les routes avec + de 500 trips ?
Un count avec un group by + distinct + jointure + having :
SELECT COUNT(DISTINCT t.trip_id), t.route_id, r.route_long_name
FROM trips AS t JOIN routes AS r USING(route_id)
GROUP BY r.route_id
HAVING COUNT(DISTINCT t.trip_id) > 500query = "select count(distinct t.trip_id), t.route_id, r.route_long_name
from trips as t join routes as r on t.route_id=r.route_id
group by r.route_id
having count(distinct t.trip_id)>500"
sqldf(query)Le stop avec le + de trips ?
Un count avec un group by + order by + limit :
SELECT COUNT(*) AS nbtrips, stop_id
FROM stop_times
GROUP BY stop_id
ORDER BY nbtrips DESC
LIMIT 1query = "select count(*) as nbtrips, stop_id
from stop_times
group by stop_id
order by nbtrips desc
limit 1"
sqldf(query)Le nombre de routes par stop ?
Un count distinct avec un group by + jointures :
SELECT COUNT(DISTINCT ro.route_id) AS nbroutes, st.stop_id, tr.trip_id
FROM stop_times AS st JOIN trips AS tr USING(trip_id)
GROUP BY stop_idquery = "select count(distinct tr.route_id) as nbroutes, st.stop_id, tr.trip_id
from stop_times as st join trips as tr on st.trip_id=tr.trip_id
group by stop_id"
sqldf(query)Les 5 stops avec le + de routes ? (avec leur noms)
Un count distinct avec un group by + jointures :
SELECT COUNT(DISTINCT tr.route_id) AS nbroutes, st.stop_id, stn.stop_name
FROM stops AS stn JOIN stop_times AS st JOIN trips AS tr
ON st.stop_id=stn.stop_id AND st.trip_id=tr.trip_id
GROUP BY st.stop_id
ORDER BY nbroutes DESC
LIMIT 5query = "select count(distinct tr.route_id) as nbroutes, st.stop_id, stn.stop_name
from stops as stn join stop_times as st join trips as tr
on st.stop_id=stn.stop_id and st.trip_id=tr.trip_id
group by st.stop_id
order by nbroutes desc
limit 5"
sqldf(query)L'heure du premier départ à chaque arrêt ?
SELECT st.stop_id, s.stop_name, MIN(st.departure_time)
FROM stop_times AS st, stops AS s
WHERE st.stop_id=s.stop_id
GROUP BY st.stop_idquery = "select st.stop_id, s.stop_name, min(st.departure_time)
from stop_times as st, stops as s
where st.stop_id=s.stop_id
group by st.stop_id"
sqldf(query)Les arrêts avec des bus la nuit entre 2h et 5h du matin ?
Un jointure + conditions ou between + distinct :
SELECT DISTINCT st.stop_id, s.stop_name, st.departure_time
FROM stop_times AS st JOIN stops AS s USING(stop_id)
WHERE st.departure_time BETWEEN '02:00:00' AND '05:00:00'query = "select distinct st.stop_id, s.stop_name, st.departure_time
from stop_times as st join stops as s on s.stop_id=st.stop_id
where st.departure_time between '02:00:00' and '05:00:00'"
sqldf(query)Lister les arrêts non accessibles aux handicapés ?
SELECT *
FROM stops
WHERE wheelchair_boarding=2query = "select stop_id, stop_name
from stops
where wheelchair_boarding=2"
sqldf(query)Calculer la durée des trips.
strftime + min, max et group by :
SELECT trip_id, MIN(arrival_time), MAX(arrival_time),
MAX(STRFTIME('%s','2014-01-01 ' || arrival_time))
- MIN(STRFTIME('%s','2014-01-01 ' || arrival_time)) as time
FROM stop_times
GROUP BY trip_idquery = "select trip_id, min(arrival_time), max(arrival_time),
max(strftime('%s',arrival_time))
- min(strftime('%s', arrival_time)) as time
from stop_times
group by trip_id"
sqldf(query)Fréquence moyenne à la station 'Gayeulles Piscine' le 23/09/2014.
(Vous pourrez utiliser un second traitement effectué en R).
Recherche de tous les passages à la station le 23 Septembre, jointures multiples et conditions sur la table calendar :
SELECT departure_time, strftime('%s','2014-09-23' || arrival_time) AS depsec
FROM stop_times AS st JOIN stops AS s JOIN trips AS tr JOIN calendar AS cal
ON s.stop_id=st.stop_id AND tr.trip_id=st.trip_id AND tr.service_id=cal.service_id
WHERE s.stop_name = 'Gayeulles Piscine' AND cal.tuesday=1
AND cal.start_date<'20140923' AND cal.end_date>'20140923'
ORDER BY st.departure_timequery = "select departure_time,
strftime('%s','2014-09-23' || arrival_time) as depsec
from stop_times as st join stops as s join trips as tr join calendar as cal
on s.stop_id=st.stop_id and
tr.trip_id=st.trip_id and tr.service_id=cal.service_id
where s.stop_name = 'Gayeulles Piscine'
and cal.tuesday=1 and cal.start_date<'20140923'
and cal.end_date>'20140923'
order by st.departure_time"
# Stockage de la requête dans la data.frame horaires
horaires = sqldf(query)
# Calcul de la fréquence moyenne
mean(diff(as.numeric(sort(horaires$depsec))))