Requêtes SQL multi-tables, triggers

Requêtes sur plusieurs tables
Clé primaire
Identifiant d'une rangée dans une table.
Exemple : Client(
ID, Nom, Prenom, DateDeNaissance),
où ID est un entier incrémenté à chaque nouveau client.
Alternative : clé = (Nom,Prénom). Inconvénients :
- Unicité ?
- Performance ?
Clé étrangère
Attribut qui est une clé primaire dans une autre table.
Exemple : Client(
ID, Nom, Prenom, DateDeNaissance)
Commande(
ID,#ClientID,Quantite,Prix,Produit,Date)
JOIN : concaténation de tables
Les requêtes nécessitent souvent plusieurs tables :
- Nom des clients ayant commandé le produit P ?
(Tables : Client,Produit) - Lieu du concert du groupe G à la date D ?
(Tables : Lieu,Groupe,Concert) - ...
Première possibilité :
SELECT Prenom, Nom
FROM Client, Produit
WHERE Client.ID = Produit.ClientID (AND autres_conditions);- peu lisible ("condition de recollement" + filtres sur les rangées) ;
- soucis de performance (syntaxe "produit cartésien").
[INNER] JOIN
SELECT Prenom, Nom
FROM Client
JOIN Produit
ON Client.ID = Produit.ClientID
WHERE possibles_filtres;- la façon dont les tables sont réunies (JOIN ... ON ...)
- les éventuelles conditions filtrant des rangées (WHERE ...)
Possible problème :
si une valeur d'attribut de jointure est absente d'une des tables,
toutes les lignes la contenant seront omises.
Exemple :
JOIN Groupe(Nom,Membres,Style), Concert(Lieu,NomGroupe,Date)
$\rightarrow$ pas d'affichage des groupes sans concerts.
OUTER JOIN
Assure que toutes les rangées des tables sont dans le résultat.
Exemple :SELECT Lieu,Nom AS Groupe
FROM Groupe
[FULL] OUTER JOIN Concert
ON Groupe.Nom = Concert.NomGroupe
WHERE possibles_filtres;- LEFT OUTER JOIN : n'ajoute que les rangées manquantes de la première table ;
- RIGHT OUTER JOIN : n'ajoute que les rangées manquantes de la seconde table.
Exercice
Client(
ID,Nom,Prenom,Adresse,Telephone)
Commande(
ID,ClientID,ProduitID,Prix,Quantité,Date)
Produit(
ID,Nom,Categorie,Description)
Afficher les prénoms+noms des clients ayant commandé une cuisine le 10 octobre 2012 (en utilisant JOIN).
SELECT cl.Prenom,cl.Nom
FROM Client AS cl
JOIN Commande AS co
ON cl.ID = co.ClientID
JOIN Produit AS p
ON co.ProduitID = p.ID
WHERE co.Date = '2012-10-10' AND p.Nom = 'Cuisine';Requêtes imbriquées
Principe : sous-requête (souvent) dans la clause WHERE.
Exemple : films loués plus souvent que la moyenne.SELECT film_id,title,rental_rate FROM film
WHERE rental_rate >
(SELECT AVG (rental_rate)
FROM film);SELECT g.Nom FROM Groupe AS g
WHERE EXISTS
(SELECT 1
FROM Concert AS c
WHERE c.NomGroupe = g.Nom);Remarque : possible aussi avec INSERT, DELETE ou UPDATE.
Requêtes imbriquées - suite
Exemple : salariés dont le salaire dépasse 45k.SELECT * FROM Company
WHERE ID IN
(SELECT ID
FROM Company
WHERE Salary > 45000);SELECT *
FROM
(SELECT Nom,Style
FROM Groupe
WHERE Nom LIKE 'E%') AS tableTemp
WHERE tableTemp.Style = 'Symphonic Metal';Requêtes imbriquées - "fin"
Exemple : commandes dont l'ID client est plus grand qu'au moins un des ID de clients ayant commandé 5 exemplaires d'un article.
SELECT * FROM Commande
WHERE ClientID > ANY
(SELECT cl.ID
FROM Client AS cl
JOIN Commande AS co ON cl.ID = co.ClientID
WHERE co.Quantite = 5);Exemple : groupes jouant dans des lieux ne se terminant pas par O.
SELECT DISTINCT Groupe.Nom
FROM Groupe
JOIN Concert ON Groupe.Nom = Concert.NomGroupe
WHERE Concert.Lieu <> ALL
(SELECT Lieu FROM Concert
WHERE Lieu LIKE '%O');Exercice
Client(
ID,Nom,Prenom,Adresse,Telephone)
Commande(
ID,ClientID,ProduitID,Prix,Quantité,Date)
Produit(
ID,Nom,Categorie,Description)
Afficher les prénoms+noms des clients ayant commandé une cuisine le 10 octobre 2012 (en utilisant des sous-requêtes).
SELECT Prenom, Nom
FROM Client
WHERE ID IN
(SELECT ClientID
FROM Commande
WHERE Date = '2012-10-10' AND ProduitID IN
(SELECT ID
FROM Produit
WHERE Nom = 'Cuisine'))WITH ...
Isole une (ou plusieurs) sous-requête(s) dont les résultats servent aux requêtes suivantes. Exemple de la doc PostgreSQL :
WITH regional_sales AS
(SELECT region, SUM(amount) AS total_sales
FROM orders GROUP BY region),
top_regions AS
(SELECT region FROM regional_sales
WHERE total_sales >
(SELECT SUM(total_sales)/10 FROM regional_sales))
SELECT region,product,SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;- Régions dont les sommes des ventes dépassent le 1/10 du total.
- Afficher ces régions en les regroupants par produits.
Les vues
Comme WITH, mais mémorise le résultat.
$\Rightarrow$ On peut l'utiliser dans d'autres requêtes.
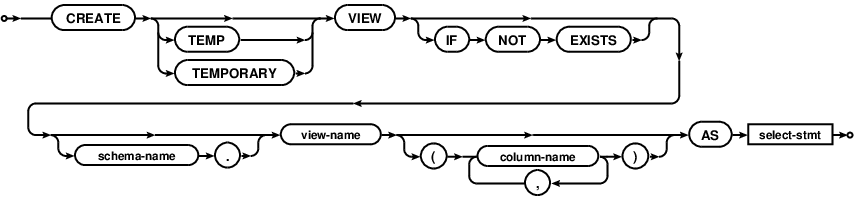
CREATE VIEW comedies AS
SELECT * FROM films WHERE kind = 'Comedy';
(...)
-- Affiche le titre du film comique emprunté
SELECT u.nom, u.prenom, c.title
FROM users AS u
LEFT OUTER JOIN comedies AS c
ON u.rentID = c.ID;WITH RECURSIVE
Illustration :
WITH RECURSIVE t(n) AS (
VALUES (1)
UNION ALL
SELECT n+1 FROM t WHERE n < 100)
SELECT sum(n) FROM t; -- affiche 5050La table t se construit "récursivement" lors de la requête finale.
- Une rangée est ajoutée avec la valeur 1 (initialisation).
- À chaque itération, la dernière rangée calculée est incrémentée et ajoutée au résultat.
Exemple d'utilisation plus réaliste
WITH RECURSIVE (détails)
- Initialisation d'une table résultat (R) avec une requête SQL simple. Recopie de ce premier résultat dans une table de travail (T)
- Tant que la table de travail n'est pas vide :
- Évaluer la requête récursive en utilisant T. Appelons le résultat "tmp"
- Ajouter le contenu de tmp dans R.
- Remplacer le contenu de T par celui de tmp
Note : avec le mot-clé UNION on élimine les doublons en 1, 2.b et 2.c ; avec UNION ALL, on les garde.
Requête SQL "factorielle"
WITH RECURSIVE rec_fact (n, fact) AS (
SELECT 1, 1 -- Requête initiale
UNION ALL
SELECT n+1, (n+1)*fact FROM rec_fact -- Requête récursive
WHERE n < 3) -- Condition d'arrêt
SELECT MAX(fact) FROM rec_fact;T
| n | fact |
|---|
tmp
| n | fact |
|---|
R
| n | fact |
|---|
| 1 | 1 |
| 1 | 1 |
| 2 | 2 |
| 2 | 2 |
| 1 | 1 |
| 2 | 2 |
| 3 | 6 |
| 3 | 6 |
| 1 | 1 |
| 2 | 2 |
| 3 | 6 |
WITH RECURSIVE : parcours de graphe
CREATE TABLE node (id INTEGER PRIMARY KEY,p_id INTEGER);
INSERT INTO node (p_id) VALUES
(NULL),(1),(2),(3),(NULL),(NULL),(NULL),(6);
WITH RECURSIVE nodes_rec(id, depth, path) AS (
SELECT id, 0, CAST (id AS TEXT)
FROM node WHERE p_id IS NULL
UNION ALL
SELECT n.id, nr.depth+1, nr.path||'->'||n.id
FROM nodes_rec AS nr JOIN node AS n ON n.p_id = nr.id)
SELECT * FROM nodes_rec AS nr ORDER BY nr.id;id depth path ---------- ---------- ---------- 1 0 1 2 1 1->2 3 2 1->2->3 4 3 1->2->3->4 5 0 5 6 0 6 7 0 7 8 1 6->8
LIKE, GLOB
expr [NOT] LIKE pattern [ESCAPE expr]- _ : remplace n'importe quel caractère ;
- % : remplace n'importe quelle sous-chaîne.
'abc' LIKE 'abc' true
'abc' LIKE 'a%' true
'abc' LIKE '_b_' true
'abc' LIKE 'c' falseSELECT Titre,Auteur
FROM Document
WHERE Auteur LIKE '%a_' -- match 'Vargas', 'Curval', etc.Triggers

Déclencher des instructions SQL quand une table est modifiée...
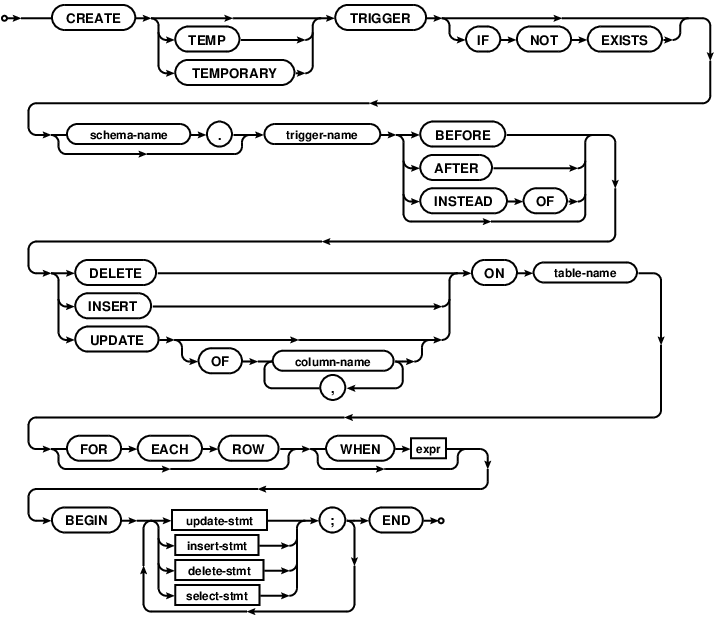
Triggers are database operations that are automatically performed when a specified database event occurs.
A trigger may be specified to fire whenever a DELETE, INSERT, or UPDATE of a particular database table occurs, or whenever an UPDATE occurs on on one or more specified columns of a table.
- ceux agissant à chaque ligne modifiée, et
- ceux agissant au niveau de l'instruction SQL
(potentiellement sur un ensemble de lignes)
Both the WHEN clause and the trigger actions may access elements of the row being inserted, deleted or updated using references of the form "NEW.column-name" and "OLD.column-name".
OLD and NEW references may only be used in triggers on events for which they are relevant, as follows:
- INSERT: NEW references are valid
- UPDATE: NEW and OLD references are valid
- DELETE: OLD references are valid
The BEFORE or AFTER keyword determines when the trigger actions will be executed relative to the target SQL instruction.
Exemple 1
The following UPDATE trigger ensures that all associated orders are redirected when a customer changes his or her address:
CREATE TRIGGER upd_cust_addr UPDATE OF address ON customers
BEGIN
UPDATE orders SET address = new.address
WHERE customer_name = old.name;
END;With this trigger installed, executing the statement:
UPDATE customers SET address = '1 Main St.'
WHERE name = 'Jack Jones';causes the following to be automatically executed:
UPDATE orders SET address = '1 Main St.'
WHERE customer_name = 'Jack Jones';Exemple 2
CREATE TABLE people (
id integer PRIMARY KEY,
first_name text NOT NULL,
last_name text NOT NULL,
email text NOT NULL,
address text,
phone text );Suppose you want to validate email address before insert into the people table. In this case, you can use a BEFORE INSERT trigger:
CREATE TRIGGER valid_email BEFORE INSERT ON people
BEGIN
SELECT
CASE WHEN NEW.email NOT LIKE '%_@__%.__%' THEN
RAISE (ABORT, 'Invalid email address')
END;
END;Exemple 2 - suite
INSERT INTO people (first_name,last_name,email)
VALUES ('John','Doe','i-am-all-wrong');Error: Invalid email address$\rightarrow$ La ligne n'est pas ajoutée.
INSERT INTO leads (first_name,last_name,email)
VALUES ('John','Doe','john.doe@sqlitetutorial.net');OK$\rightarrow$ La ligne est bien insérée.
Custom functions in requests
On a parfois envie d'appliquer une transformation particulière à un résultat de requête, ou encore d'agréger des valeurs autrement qu'en les sommant ou comptant.
$\rightarrow$ C'est possible !
Limitation : on ne peut pas définir de nouvelles instructions SQL agissant au niveau de la table – sauf à agir directement en C dans le code de SQLite avant de le recompiler...
Procédures stockées ? Y'en a pas.
I think a key reason for having stored procs in a database is that you're executing SP code in the same process as the SQL engine. This makes sense for database engines designed to work as a network connected service but the imperative for SQLite is much less given that it runs as a dyn-lib in your application process rather than in a separate SQL engine process. So it makes more sense to implement all your business logic in the host language.
You can however extend SQLite with your own user defined functions in the host language (PHP, Python, Perl, C#, Javascript, Ruby etc). You can then use these custom functions as part of any SQLite select/update/insert/delete.
Dans la documentation...
Create Or Redefine SQL Functions
int sqlite3_create_function(
sqlite3 *db,
const char *zFunctionName,
int nArg,
int eTextRep,
void *pApp,
void (*xFunc)(sqlite3_context*,int,sqlite3_value**),
void (*xStep)(sqlite3_context*,int,sqlite3_value**),
void (*xFinal)(sqlite3_context*) );
// [...]These functions are used to add SQL functions or aggregates or to redefine the behavior of existing SQL functions or aggregates.
- db: database connection to which the SQL function is to be added.
- zFunctionName: name of the SQL function.
- nArg: [...]
Python + sqlite3 = easier
create_function(name, num_params, func)A function that you can later use from within SQL statements.
num_params = -1 if the function may take any number of arguments.
The function can return any of the types supported by SQLite: bytes, str, int, float and None. Example:
import sqlite3
import hashlib
def md5sum(t):
return hashlib.md5(t).hexdigest()
con = sqlite3.connect(":memory:")
con.create_function("md5", 1, md5sum)
cur = con.cursor()
cur.execute("select md5(?)", (b"foo",))
print(cur.fetchone()[0])
# Affiche acbd18db4cc2f85cedef654fccc4a4d8create_aggregate(name, num_params, aggregate_class)Creates a user-defined aggregate function. Example:
import sqlite3
class MyProd:
def __init__(self):
self.prod = 1
def step(self, value):
self.prod *= value
def finalize(self):
return self.prod
con = sqlite3.connect(":memory:")
con.create_aggregate("myprod", 1, MyProd)
cur = con.cursor()
cur.execute("create table test(i integer)")
cur.execute("insert into test values (2),(3)")
cur.execute("select myprod(i) from test")
print(cur.fetchone()[0])
# Affiche 6Un peu de regexp
import sqlite3
import re
def re_match(pattern, expression):
return bool(re.search(pattern, expression))
con = sqlite3.connect(":memory:")
con.create_function("re_match", 2, re_match)
cur = con.cursor()
cur.execute("select re_match(?,?)", ("^f","foo",))
print(cur.fetchone()[0])
# Affiche 1
cur.execute("select re_match(?,?)", ("^o","foo",))
print(cur.fetchone()[0])
# Affiche 0Les regexps en un slide
regexp_match(pattern, string)- /^foo/ : string commence par "foo"
- /foo$/ : string termine par "foo"
- /^bla$/i : string == "bLa" ou "BlA" ou ...
- /^[a-z]+$/ : seulement des minuscules (1..n)
- /^https?/ : commence par "http", ou "https"
- /^\s*def/ : commence par "def" après 0..n blancs
- /^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$/ : email
Motifs conditionnels, captures :
- /q(?!u)/ : match "Iraq" mais pas "quit"
- /q(?=u)/ : match "quit" mais pas "Iraq"
- /(\w+)/gi : capture les mots (anglais...)
- /foo([^\d]*)/ : capture un nombre suivant "foo"
Bilan
On n'a pas fait le tour de tout le langage SQL, mais suffisamment pour pouvoir écrire tout type de requête.
Et pour le reste, google + stackoverflow + ... sont vos amis ☺
Pour réviser en s'amusant (un peu ?) pendant les vacances :
Écrire les requêtes du réseau social est une bonne idée également.